Selective Attention Network
To train a Selective Attention Model, you can either use the default training setting or define your own.
Selecting Training Settings Using Slider Bar
If you are in "Free" or "Premium" subscription, you can control the training settings using a slider bar.
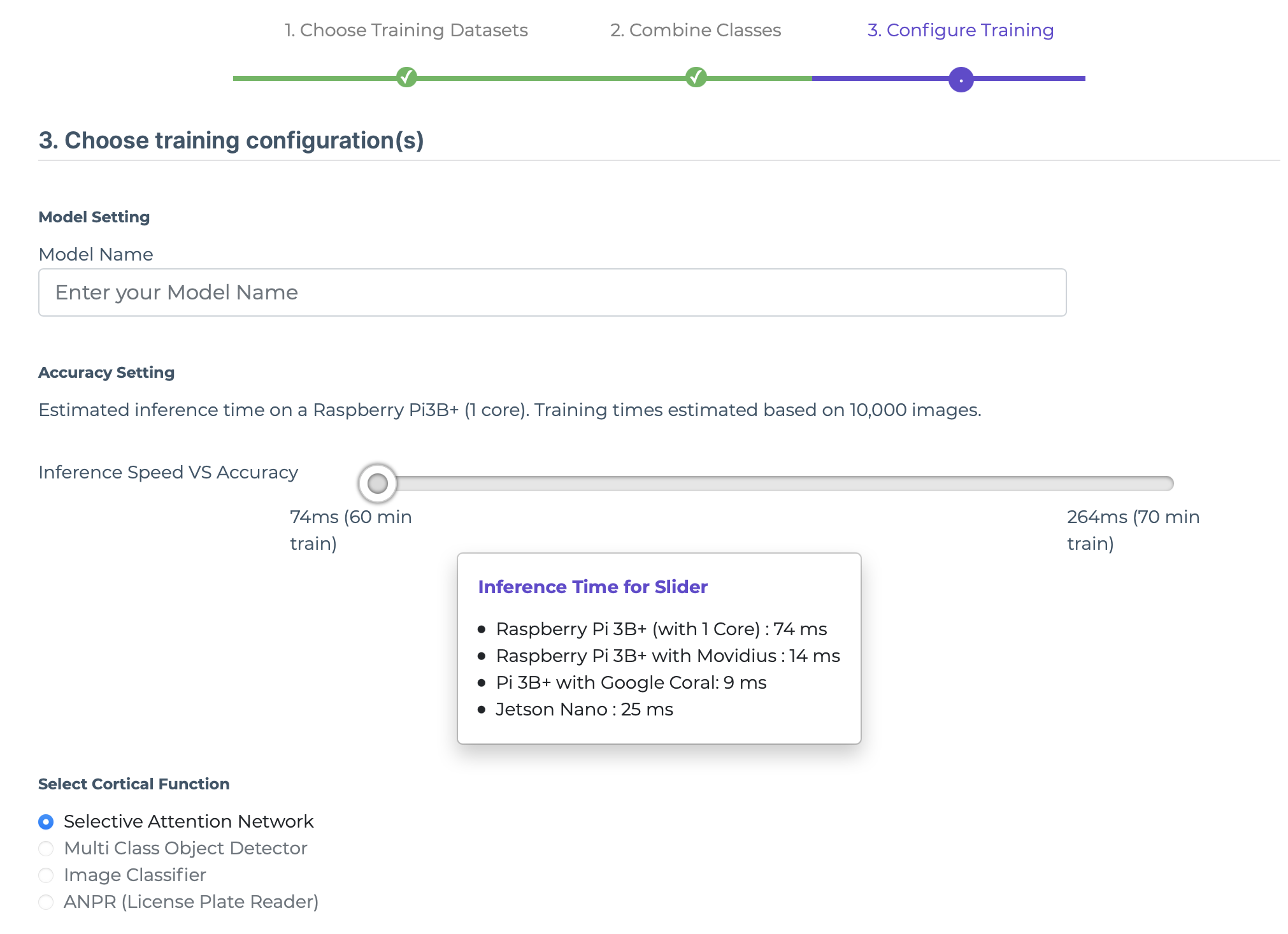
Select a value for Inference Speed vs Accuracy.
Note
1 is the fastest. It is best for larger objects with simple backgrounds. You should select option 1 if your objects of interest are medium to big (close range).
2 is slower than 1 and should be used if your objects of interest are small to medium (medium range).
Selecting Training Settings Using Configuration File
If you are in "Admin" subscription, you can upload a training configuration file to defie the training settings. The training configuration file gives you full control of the hyperparameters for the training.
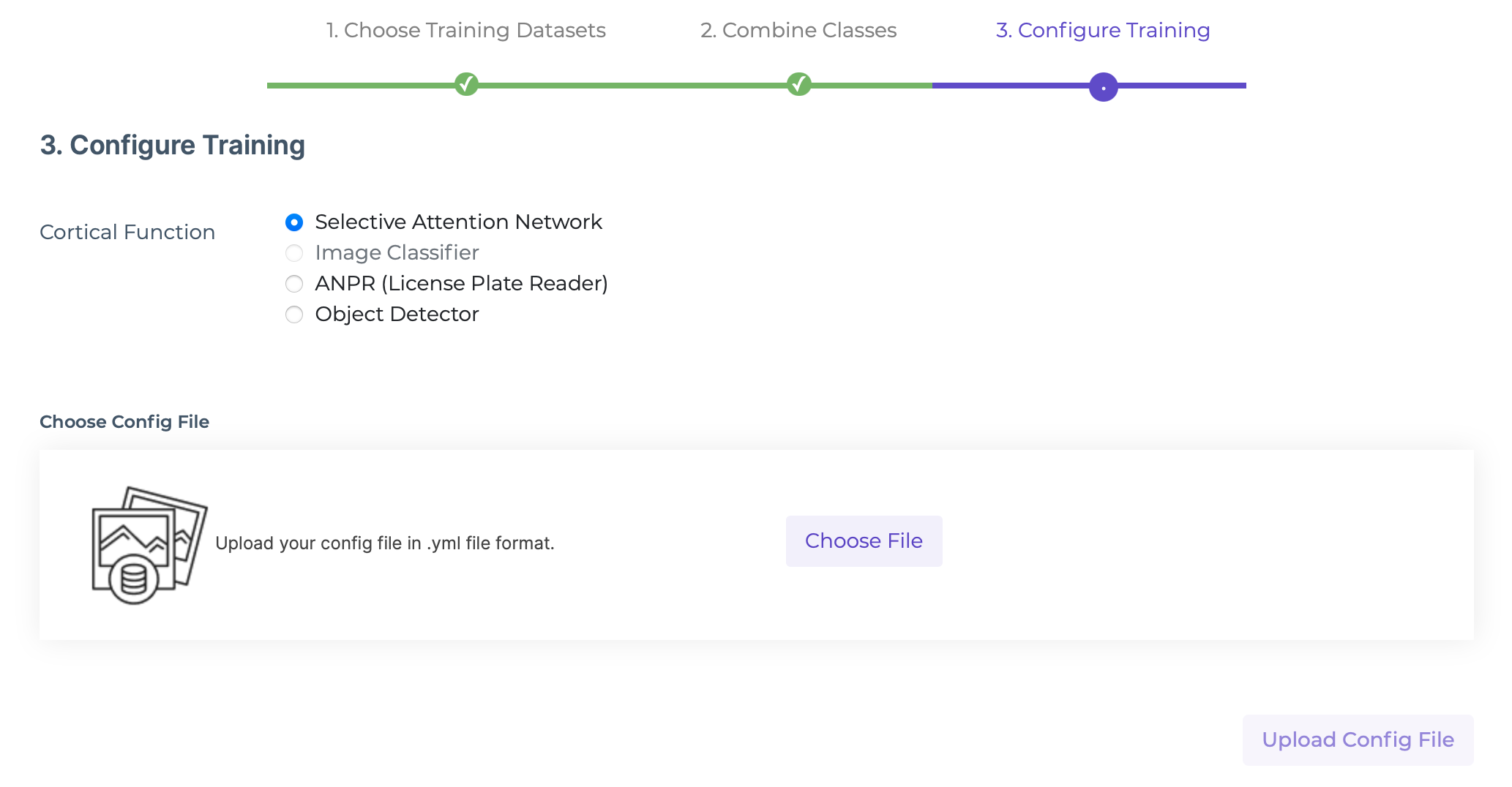
These are the settings you can modify:
- data -> input_dim: input_dim is the input resolution to the network to be trained. The input_dim must be a multiple of 32. Minimum value is 64 and maximum value is 1024. For e.g. 64, 96, 128, 160, ..., 1024.
Guide
- Use 64 if your objects of interest are large sizes (e.g. faces up to 1 m away or vehicles up to 5 m away).
- Use 128 if your objects of interest are small to medium sizes (e.g. faces up to 3 m away or vehicles up to 20 m away).
- Use 256 if your objects of interest are tiny sizes (e.g. faces up to 10 m away or vehicles up to 200 m away).
-
train -> batch_size: The batch size is a number of samples processed before the model is updated. The size of a batch must be more than or equal to one and less than or equal to the number of samples in the training dataset.
-
train -> epochs: The number of epochs is the number of complete passes through the training dataset. The number of epochs can be set to an integer value between one and infinity.
-
train -> augment_multiplier: You can use this setting to augment your training data. 1 means add 1x to the dataset (double it). 2 means add 2x (triple it).
Some other settings:
-
train -> max_negative_sampling_ratio: Ratio of negative example sampling. Ratio = negative examples / positive examples You can keep all the other setting to default.
-
test -> split_ratio: This is a ratio for splitting a held-out test set from your dataset. The held-out test set will not be used for training. It will only be used when evaluating the model once training is completed. If value is 0.1 = 10% of dataset is split into held-out test set, and the model will be trained using remaining 90% of the data.
-
transforms: Transform settings are used to define specific transformations for data augmentation. If the value for augment_multiplier is greater than 0, you can modify the transforms settings depending on how you want to augment your training dataset.
To apply RandomRotate and RandomCrop transforms, you also need to set p value to greater than 0. p = probability between 0 and 1. If p is 0 then that transform is not applied. If p is 0.5 then half the original images get transformed. If it's 1 then all the original images get transformed.
Here is the default configuration for training a Selective Attention Network.
data:
input_dim: 256
train:
batch_size: 64
epochs: 100
max_negative_sampling_ratio: 0.3 # Ratio of negative example sampling. Ratio = negative examples / positive examples
augment_multiplier: 0 # 1 means add 1x to the dataset (double it). 2 means add 2x (triple it).
test:
split_ratio: 0.1
transforms:
HorizontalFlip: False
VerticalFlip: False
Rotate:
RandomRotate:
p: 0
rotate_min: -180
rotate_max: 180
Rotate90: False
RandomCropScale: False
ShiftScaleRotate: False
RandomCrop:
p: 0
height: 118
width: 118
Noise: False
Contrast: False
Blur: False
Distort: False
Cutout:
num_holes: 0
hole_size: 25
optimizer:
name: 'Adam' # Choices: ['Adam']
params:
lr: 1.0e-3 # learning rate or step size.